# A tibble: 32 × 11
mpg cyl disp hp drat wt qsec vs am gear carb
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 21 6 160 110 3.9 2.62 16.5 0 1 4 4
2 21 6 160 110 3.9 2.88 17.0 0 1 4 4
3 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1
4 21.4 6 258 110 3.08 3.22 19.4 1 0 3 1
5 18.7 8 360 175 3.15 3.44 17.0 0 0 3 2
6 18.1 6 225 105 2.76 3.46 20.2 1 0 3 1
7 14.3 8 360 245 3.21 3.57 15.8 0 0 3 4
8 24.4 4 147. 62 3.69 3.19 20 1 0 4 2
9 22.8 4 141. 95 3.92 3.15 22.9 1 0 4 2
10 19.2 6 168. 123 3.92 3.44 18.3 1 0 4 4
# ℹ 22 more rowsR语言如何绘制相关性热图
什么是相关性热图?
相关性是指两个或多个变量之间的关系或相互影响程度。若两组的值一起增大,我们称之为正相关,若一组的值增大时,另一组的值减小,我们称之为负相关。其值介于-1与1之间,即越接近1,越正相关;越接近-1,越负相关。
常见的有两种计算相关性的算法:皮尔逊相关性(pearson)和斯皮尔曼相关性(spearman)。皮尔逊相关性最常用,适合正态分布的数据。斯皮尔曼相关性是秩相关,不受极大极小值的影响。
在组学中的应用,例如,两个技术性重复实验的结果相关性很低,则说明数据有异常。
需要注意的地方,做样本之间的相关性的时候,蛋白之间要对应,不可随意打乱顺序。数据中有缺失值的情况,通常用”pairwise.complete.obs”算法处理缺失值,即两两配对删除缺失值。
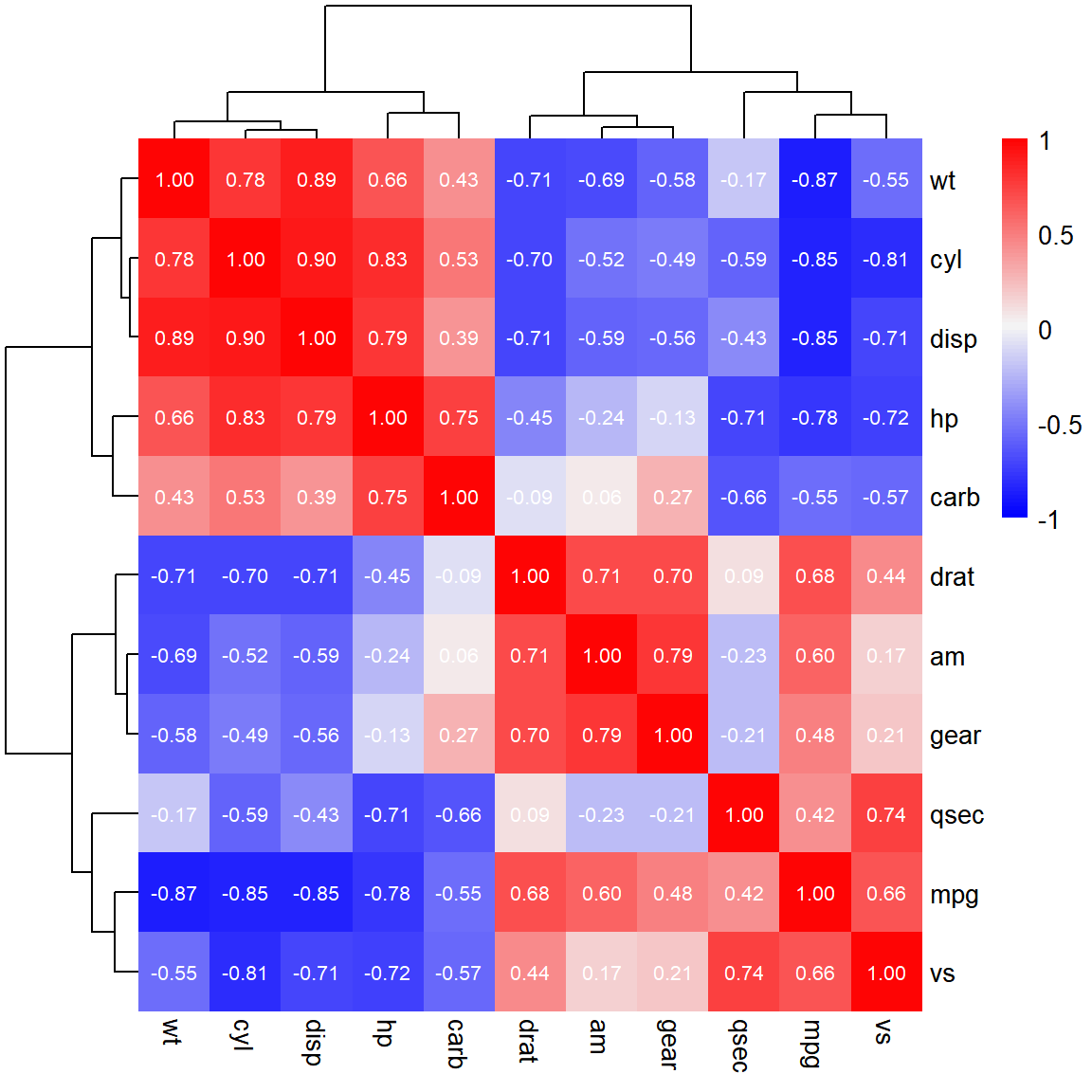
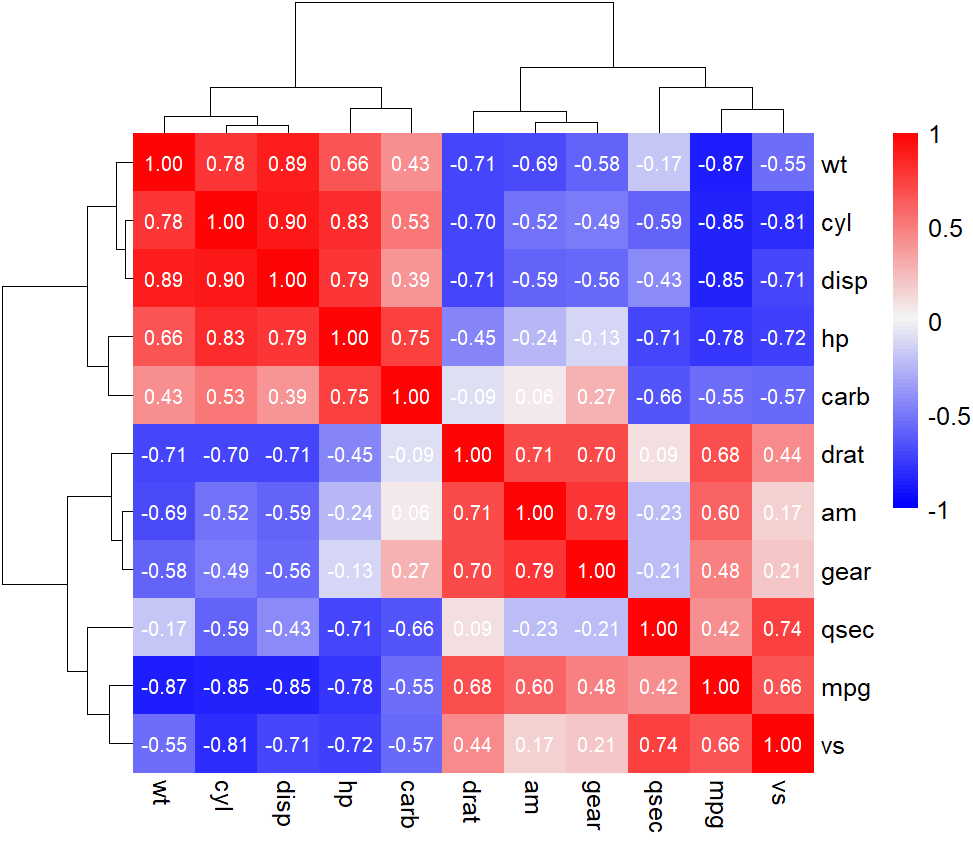
相关性热图就是,用热图的形式展现出相关性的结果。
绘图前的数据准备
这里就用R语言自带的示例数据了,mtcars
R语言如何绘制相关性热图
# 代码来源:https://www.r2omics.cn/
# 加载R包,没有安装请先安装 install.packages("包名")
library(pheatmap)
# 读取相关性热图数据文件
df= mtcars
# 计算相关性
r <- cor(df,
method = "pearson", # 计算相关性的方法有"pearson", "spearman", "kendall"
use = "pairwise.complete.obs" # 缺失值处理的方式
)
# 绘制热图
pheatmap(r,
show_colnames = TRUE, # 是否显示列名
show_rownames=TRUE, # 是否显示行名
fontsize=10, # 字体大小
color = c(colorRampPalette(c("blue", "#f3f3f4"))(50),
colorRampPalette(c("#f3f3f4", "red"))(50)), # 指定热图的颜色
breaks=c(seq(-1,1,length.out=100)),
display_numbers=T,
number_color="white",
number_format = "%.2f",
annotation_legend=TRUE, # 是否显示图例
border_color=NA, # 边框颜色 NA表示没有
scale="none", # 指定归一化的方式。"row"按行归一化,"column"按列归一化,"none"不处理
cluster_rows = TRUE, # 是否对行聚类
cluster_cols = TRUE # 是否对列聚类
)