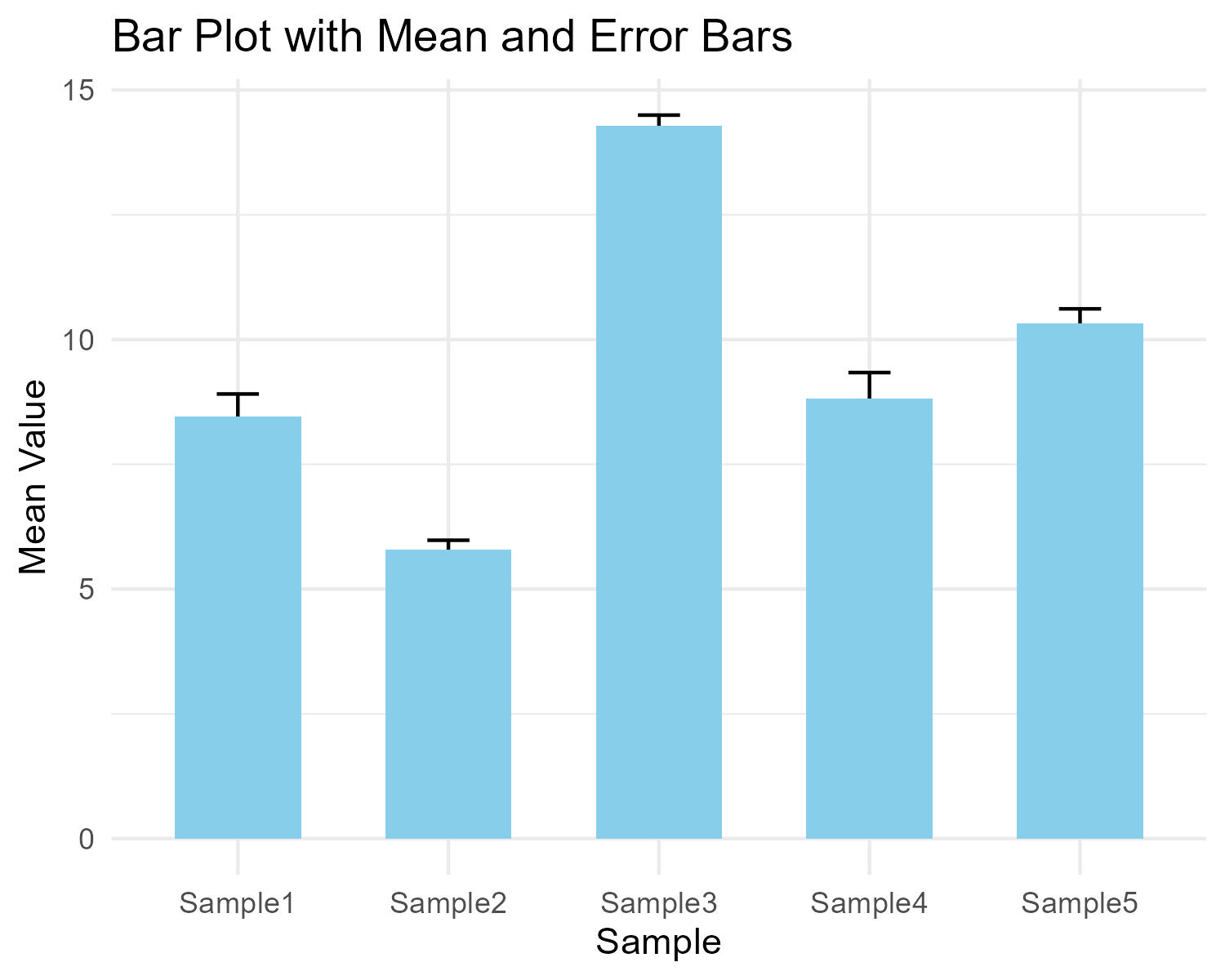
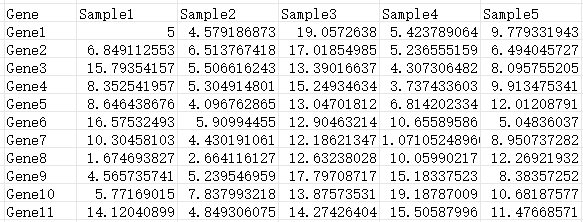
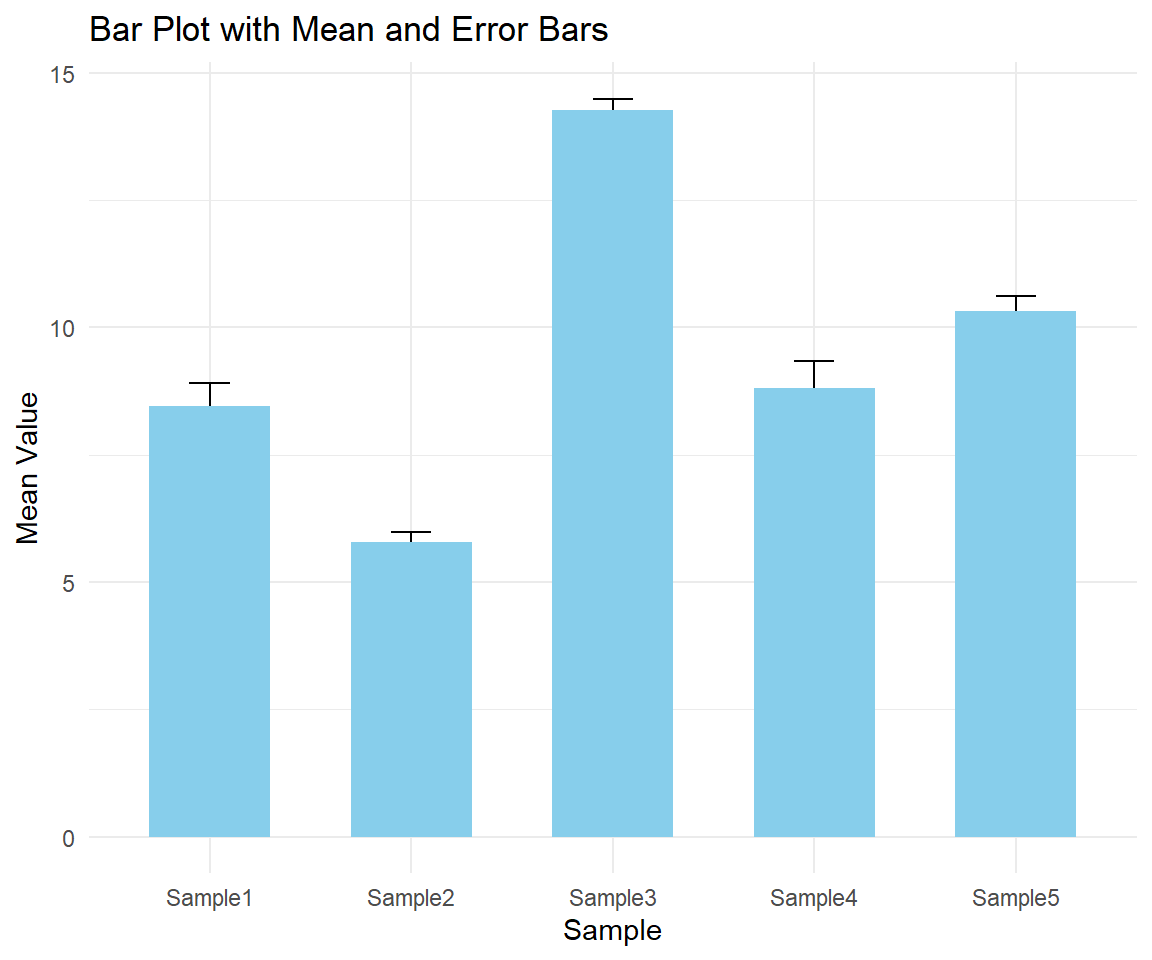# 来源 https://www.r2omics.cn/
library(tidyverse)
# 读取数据文件
df = read.delim("https://www.r2omics.cn/res/demodata/errorBar.txt") # 将此处换成你自己电脑里的文件
# 计算均值和标准误差
summary_data <- df %>%
pivot_longer(-1,names_to = "Sample",values_to = "Value") %>%
group_by(Sample) %>%
drop_na() %>% # 去除NA
summarise(
mean = mean(Value), # 计算平均追
se = sd(Value) / sqrt(n()) # 计算标准误
)
# 绘制带误差条的柱形图
ggplot(summary_data, aes(x = Sample, y = mean)) +
geom_errorbar(aes(ymin = mean - se, ymax = mean + se), width = 0.2) + # 添加误差条
geom_bar(stat = "identity", fill = "skyblue", width = 0.6) + # 创建柱形图
theme_minimal() + # 设置简洁主题
labs(title = "Bar Plot with Mean and Error Bars", x = "Sample", y = "Mean Value")