# A tibble: 584 × 5
Accession sample1 sample2 sample3 sample4
<chr> <dbl> <dbl> <dbl> <dbl>
1 protein1 283357. 594651. 898836. NA
2 protein2 69947. NA NA 72670.
3 protein3 3040433. 6045008. 5557890. 880163.
4 protein4 142188. 805093. 291644. NA
5 protein5 226066. 540079. NA NA
6 protein6 NA NA 795193. NA
7 protein7 750025. NA 783639. 232648.
8 protein8 NA 503316. NA NA
9 protein9 NA 357599. NA NA
10 protein10 455081. 812196. 962574. NA
# ℹ 574 more rowsR语言如何绘制累积曲线
什么是累积曲线?
累积曲线,全称是”经验累积分布函数”(ecdf)
在X轴映射所有数值,在Y轴映射排名的累积占比。最后通过点图和梯度连接线来进行可视化数据。就出现了简单的经验累积分布函数(ecdf)
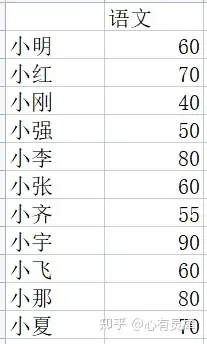
为了理解这个抽象的概念,我们用学生成绩表的累积曲线举个例子。 学生的语文成绩如下: 第一列是学生名称,第二列是语文成绩。
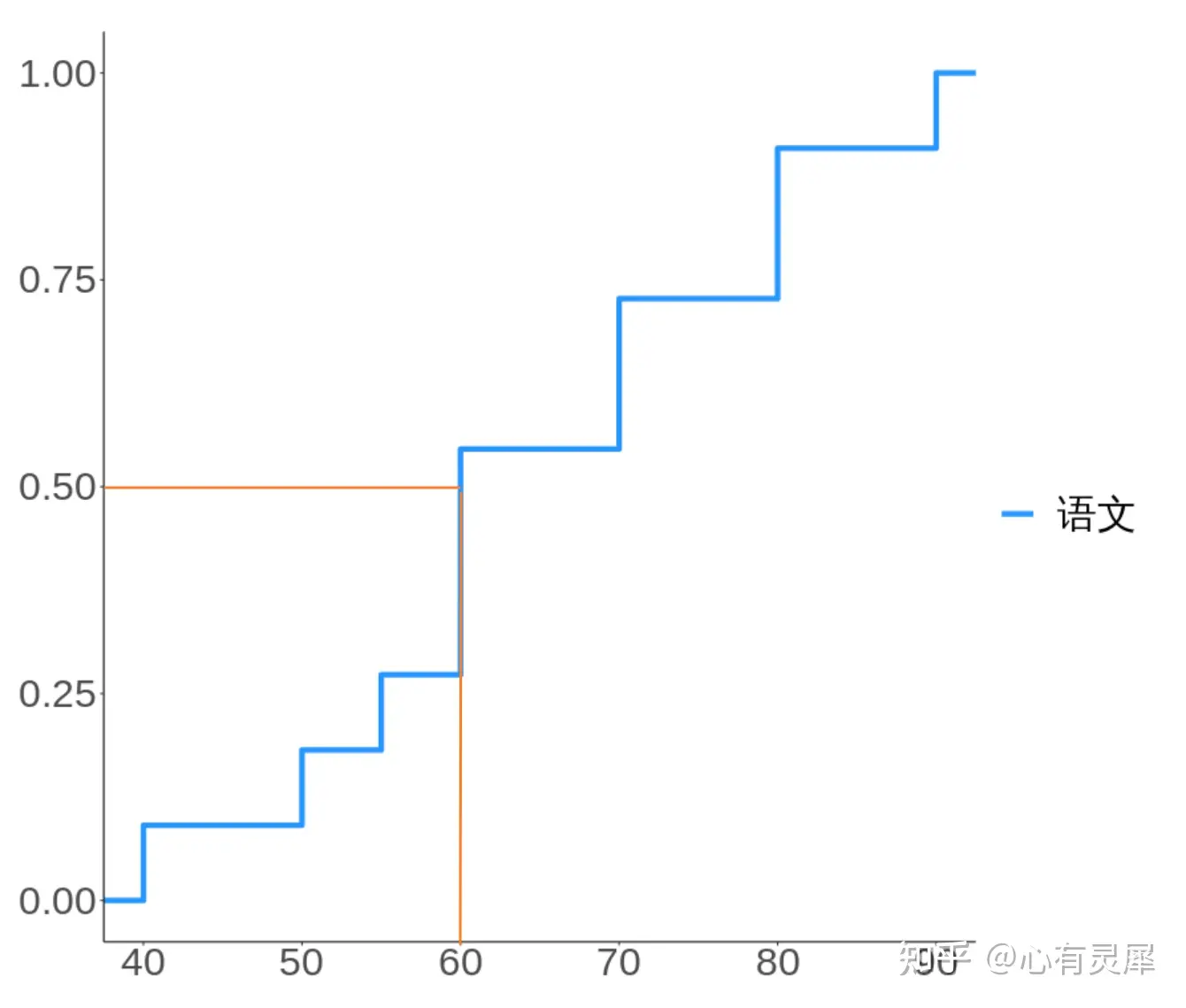
绘图时,数据会按照从小到大排序并计数,根据所占总数的比例,不断累积,最终如下图的蓝色所示。
从图中可以看出(红线),有50%的学生语文成绩在60分以下。
绘图前的数据准备
demo数据可以在https://www.r2omics.cn/res/demodata/ecdf.txt下载。
包含2个维度的数据,用生物学常用的搜库结果举例。每一列是个样本,每一行是个基因。
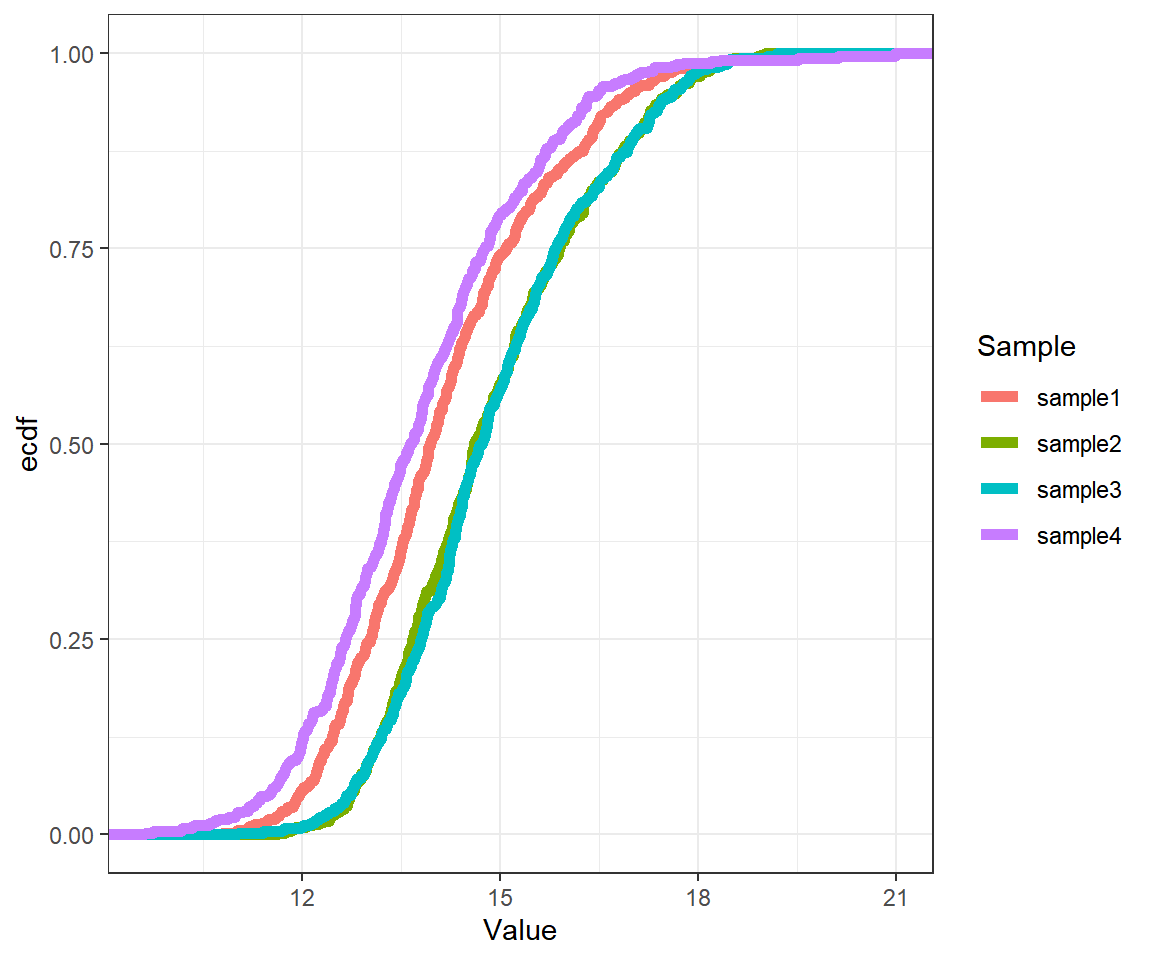
R语言如何绘制累积曲线
# 代码来源:https://www.r2omics.cn/
# 加载R包,没有安装请先安装 install.packages("包名")
library(tidyverse)
# 读取累积曲线数据文件
df = read.delim("https://www.r2omics.cn/res/demodata/ecdf.txt")
# 把数据转换成ggplot常用的类型(长数据)
df = df %>%
pivot_longer(-1,names_to = "Sample",values_to = "Value")
df$Value = log(df$Value) # 为方便观察,做log变化,以实际数据是否需要为准
# 绘图
ggplot(df,
aes(
x=Value,
color=Sample
))+
stat_ecdf( # ggplot2中的经验累积分布函数
size=2 # 线条粗细
)+
theme_bw()